
FocuSee
Freemium

Marengo 3.0은 영상, 오디오, 텍스트를 융합해 인간처럼 영상을 이해하는 강력한 AI 모델입니다. 영상 속 정보를 정확하게 검색하고 추출해야 하는 분들께 유용합니다.

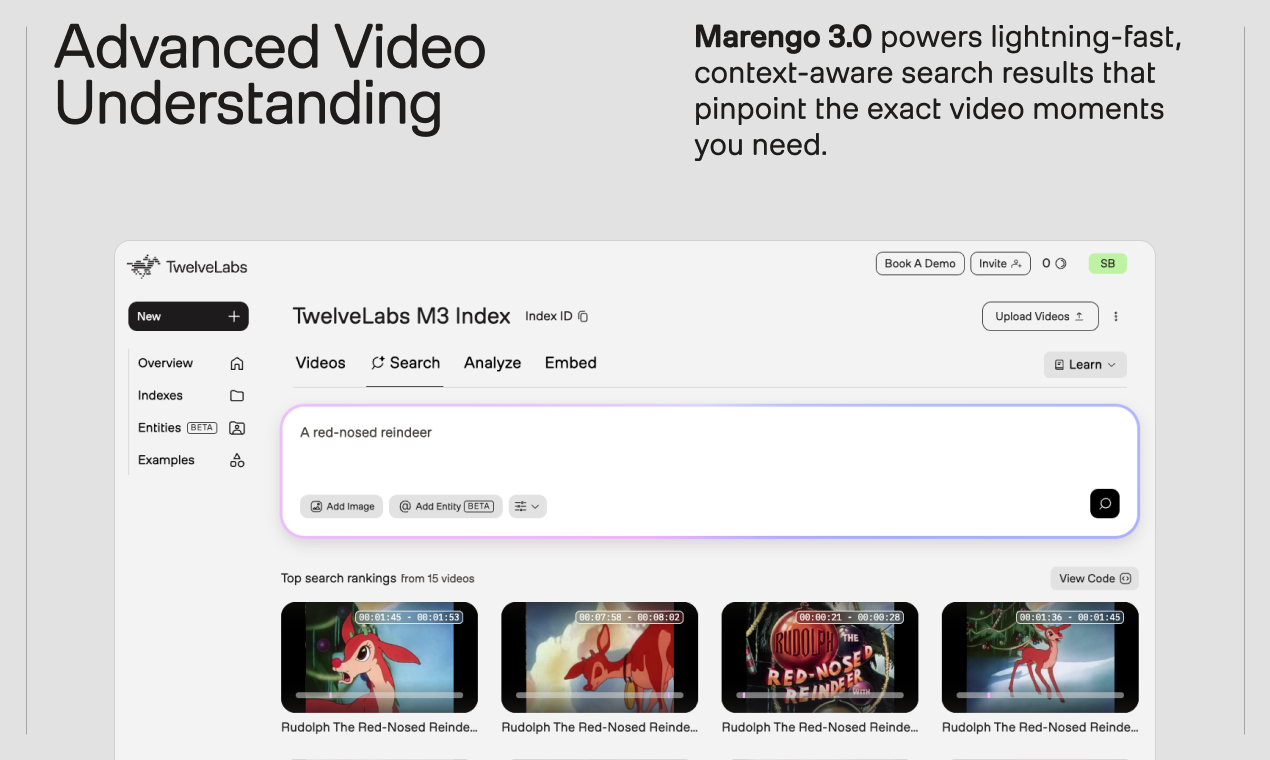
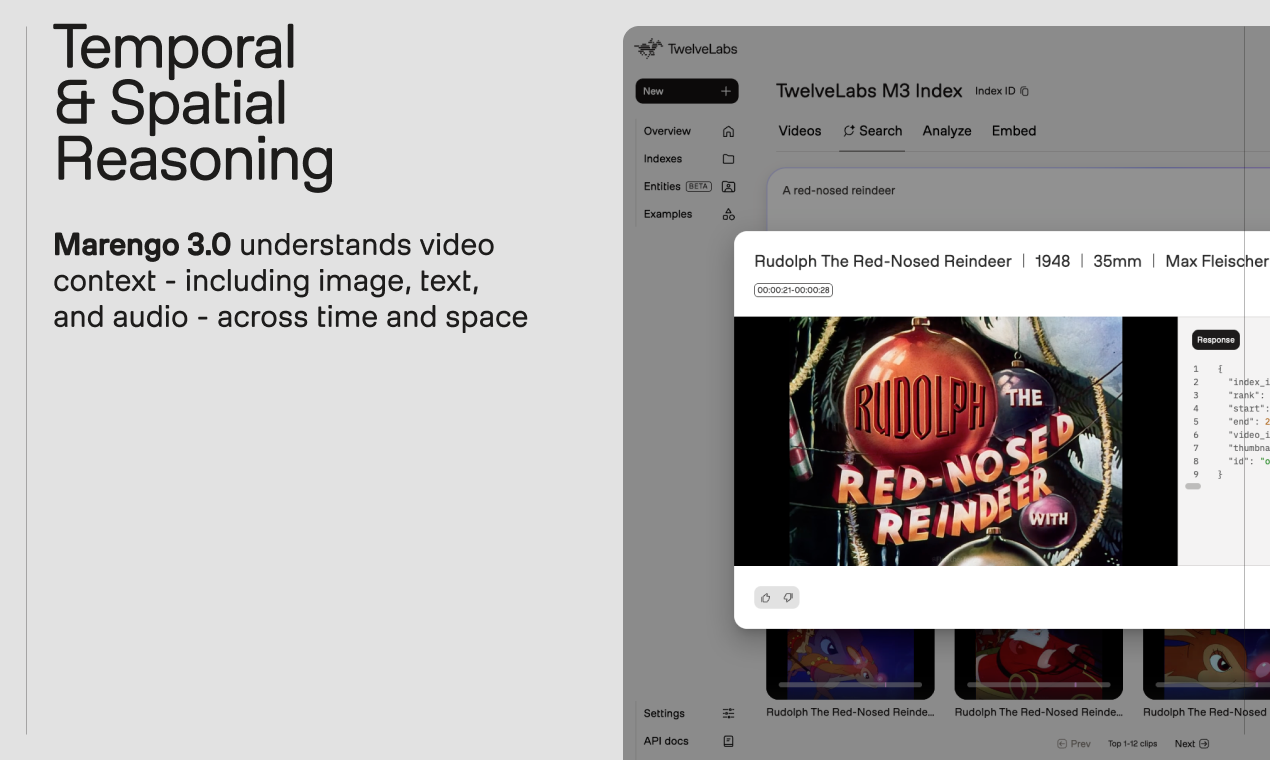
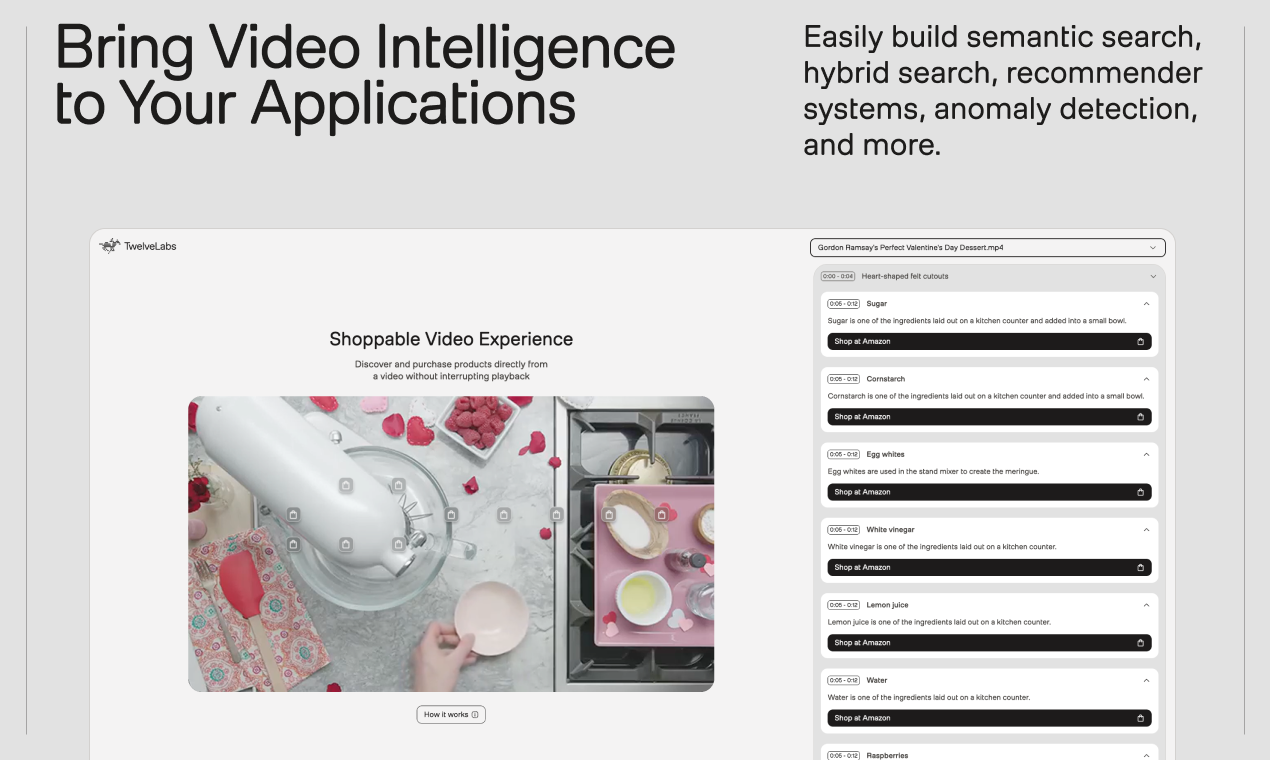

Marengo 3.0은 TwelveLabs에서 개발한 영상 이해를 위한 최신 임베딩 모델입니다. 이 모델은 영상, 오디오, 텍스트 데이터를 통합적으로 분석하여 인간과 유사한 수준의 깊이 있는 영상 이해를 가능하게 합니다.
Marengo 3.0을 사용하면 영상 콘텐츠를 단순히 시청하는 것을 넘어, 영상 속 특정 장면이나 정보를 정확하게 검색하고 추출할 수 있습니다. 예를 들어, 영상에서 특정 인물이 등장하는 장면을 찾거나, 특정 이벤트가 발생하는 시점을 파악하는 등 정밀한 영상 분석이 가능해집니다. 이는 방대한 영상 자료를 효율적으로 관리하고 활용해야 하는 다양한 분야에서 큰 도움이 될 것입니다.




