
Respan Gateway
Freemium

SemanticGuard는 반복적인 LLM 호출을 캐싱해 API 비용을 40~70%까지 절감해주는 솔루션입니다. 개발자라면 누구나 쉽게 적용할 수 있습니다.
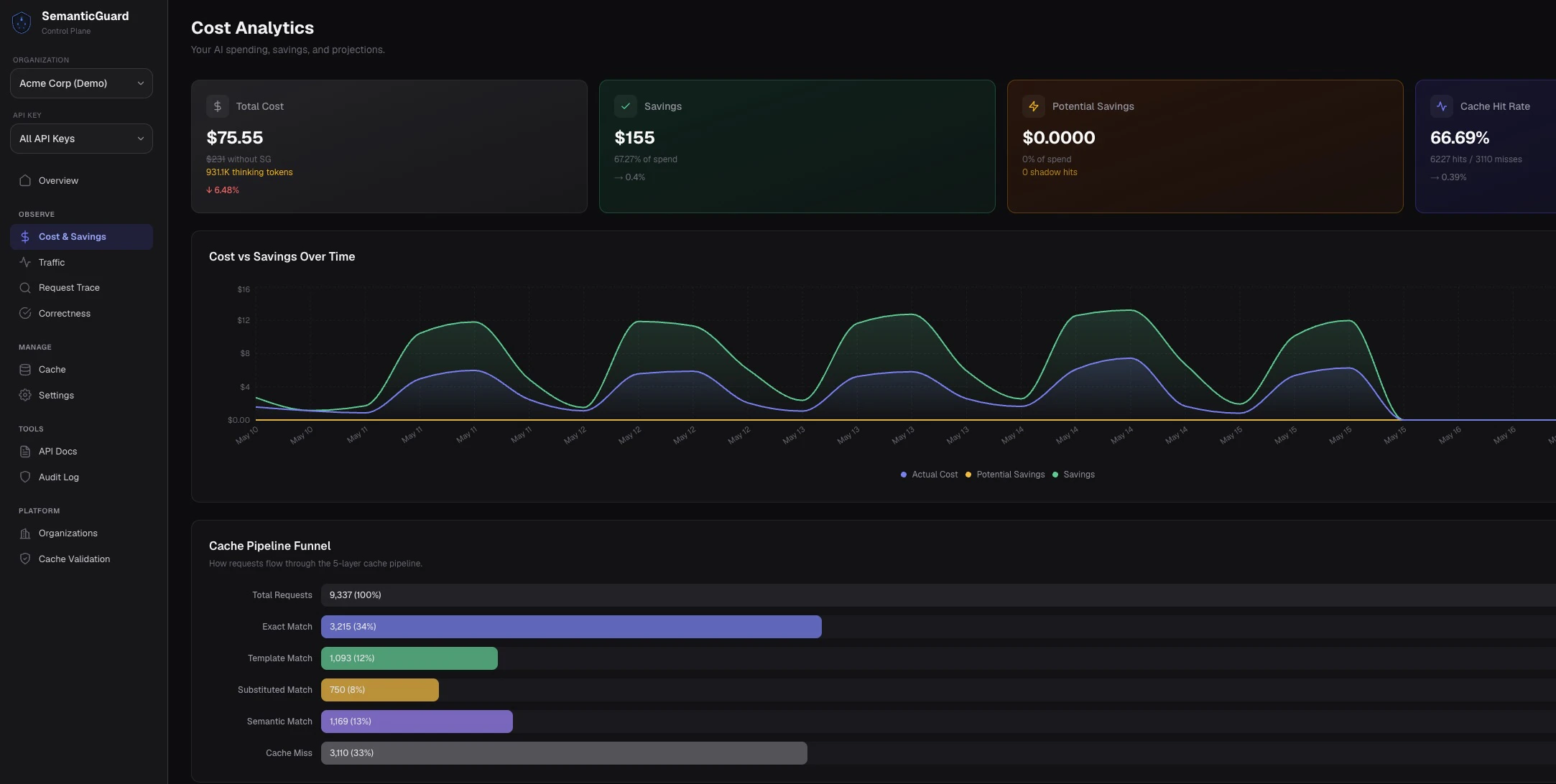
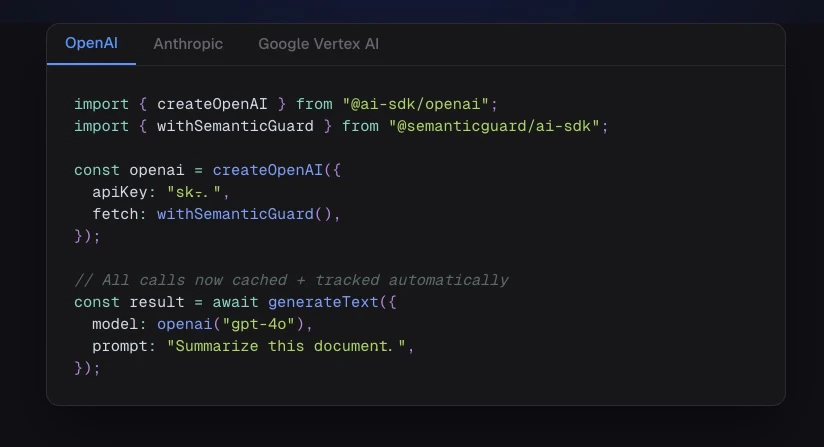
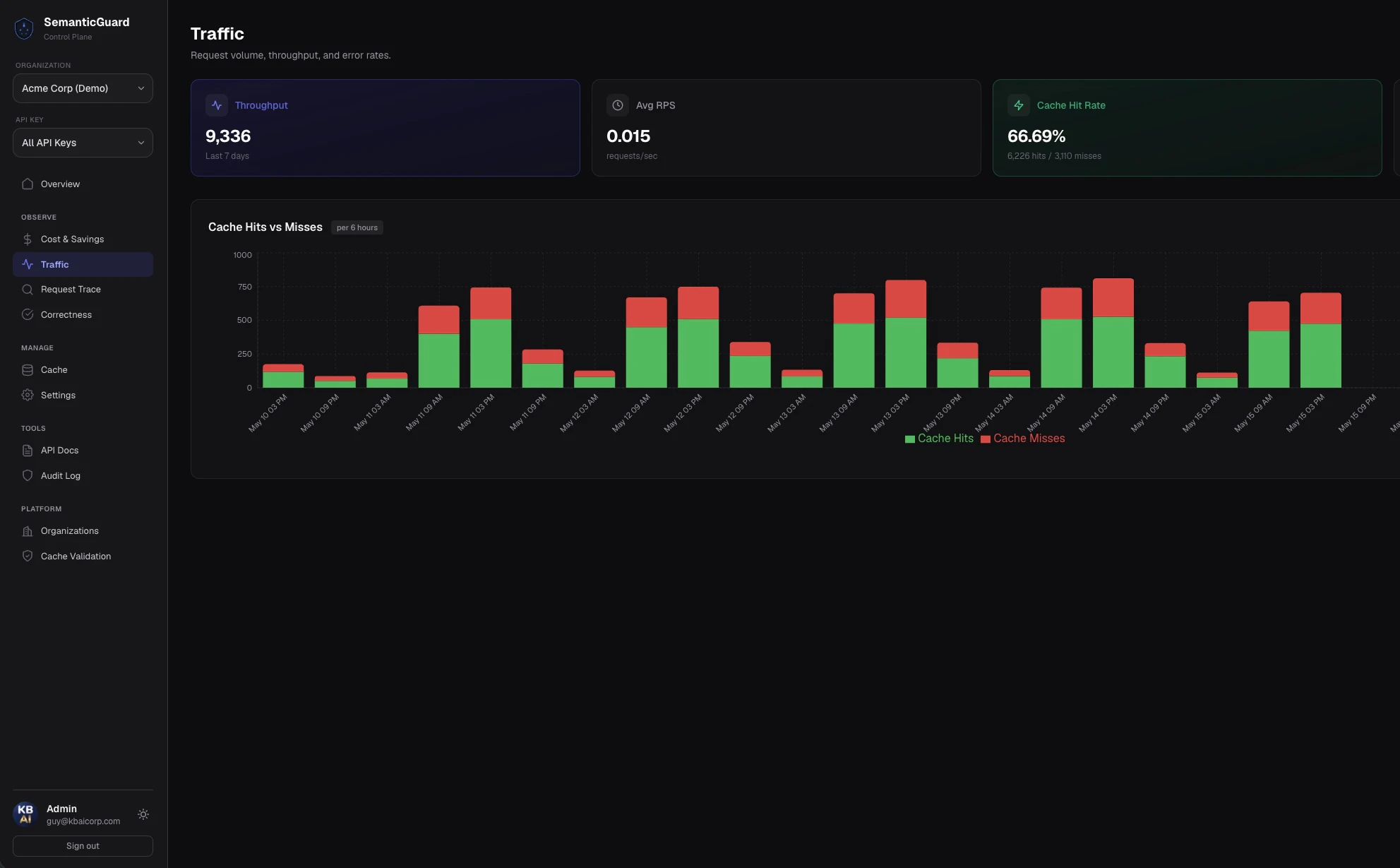
대부분의 LLM 호출은 반복됩니다. SemanticGuard는 이러한 반복적인 호출을 캐싱하여 앱과 OpenAI/Anthropic/Google 사이에 위치하며, 캐시 적중 시 50ms 미만으로 응답하여 비용을 크게 절감합니다. 한 줄의 코드로 설치 가능하며, 섀도우 모드를 통해 캐싱 활성화 전 예상 절감액을 확인할 수 있습니다. 모든 캐시 적중은 자체 AI로 검증되어 잘못된 답변을 제공할 염려가 없습니다.




